Create project
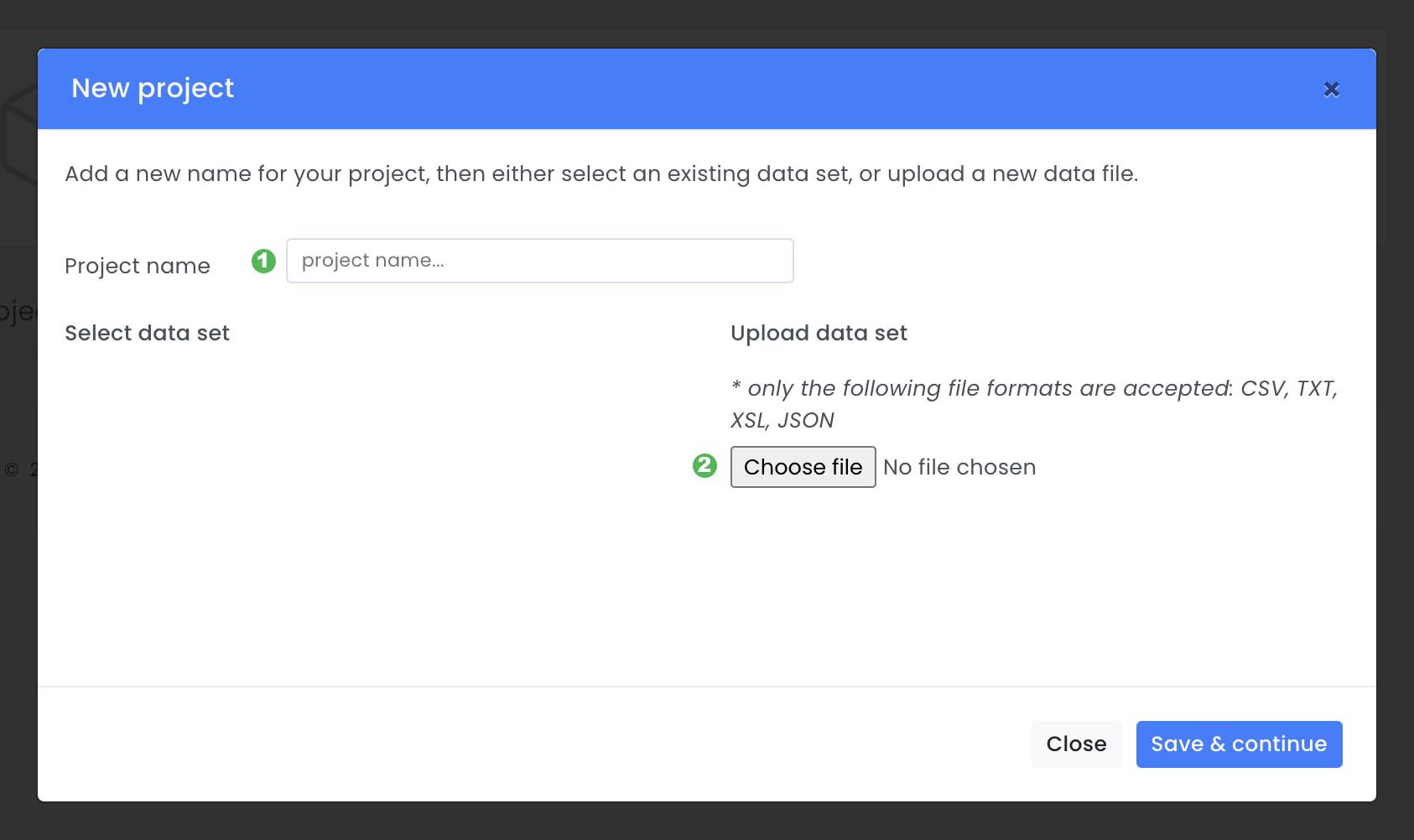
The first step is to create a project and add the dataset. To create a new project, click on New Project in the Projects view.
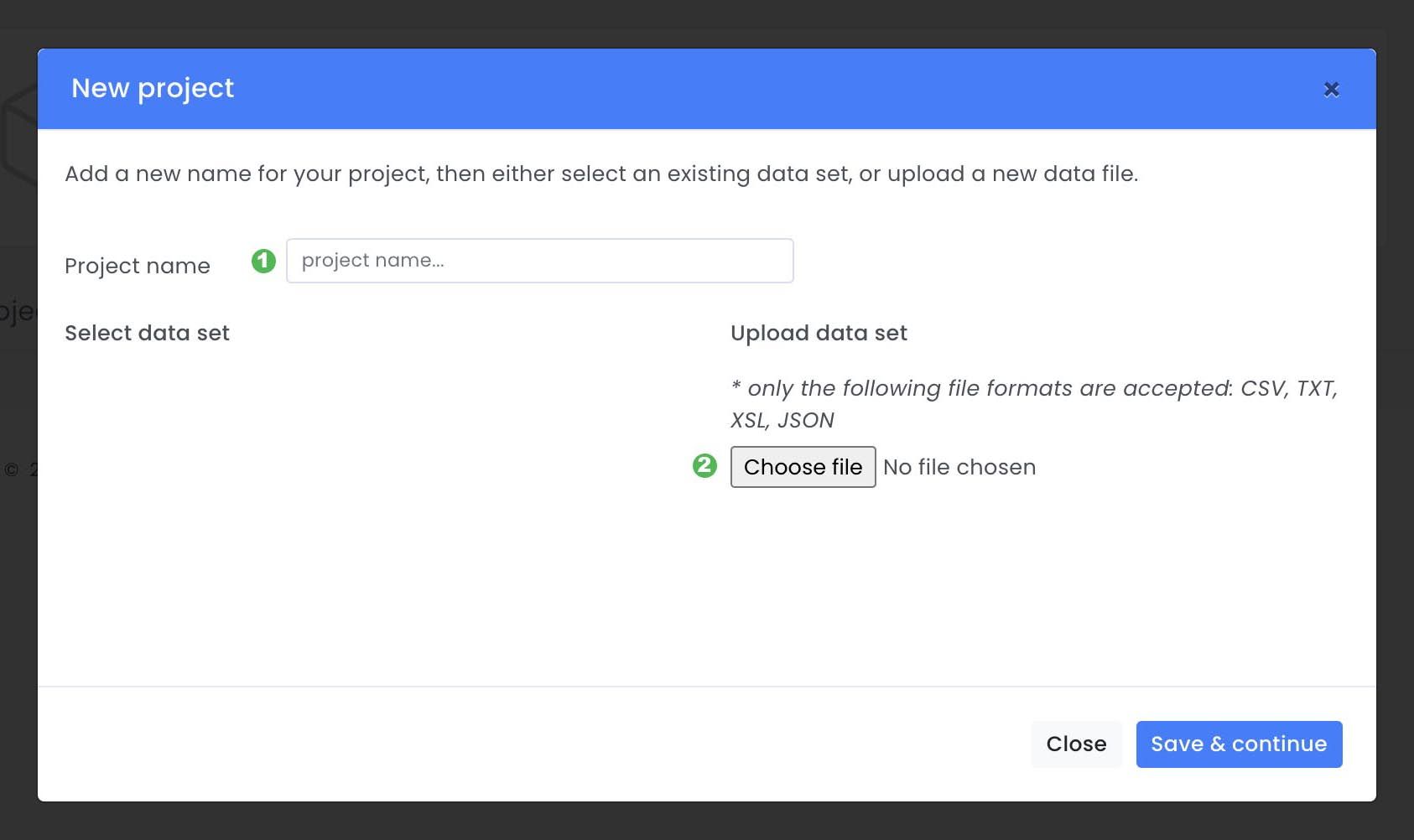
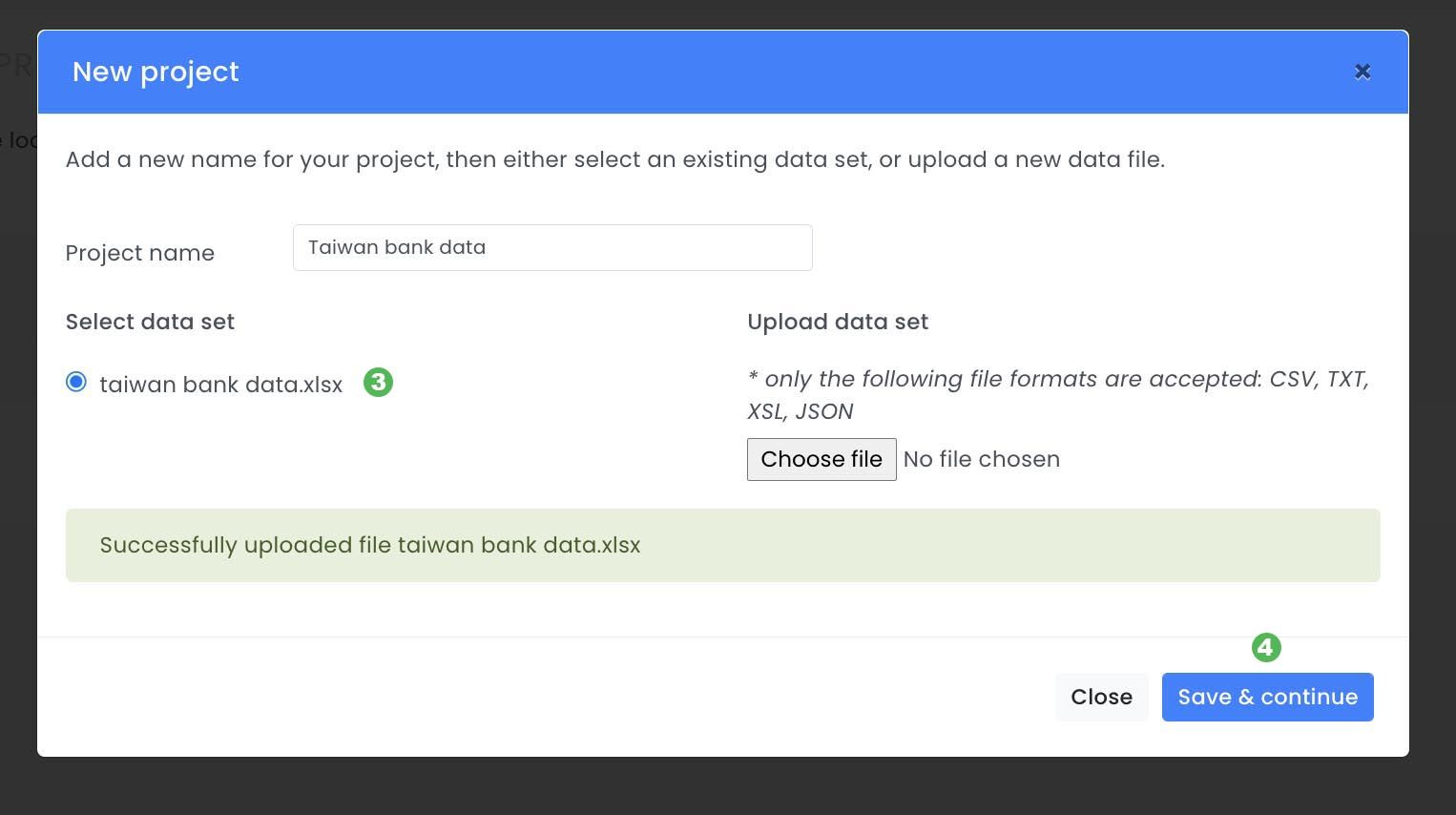
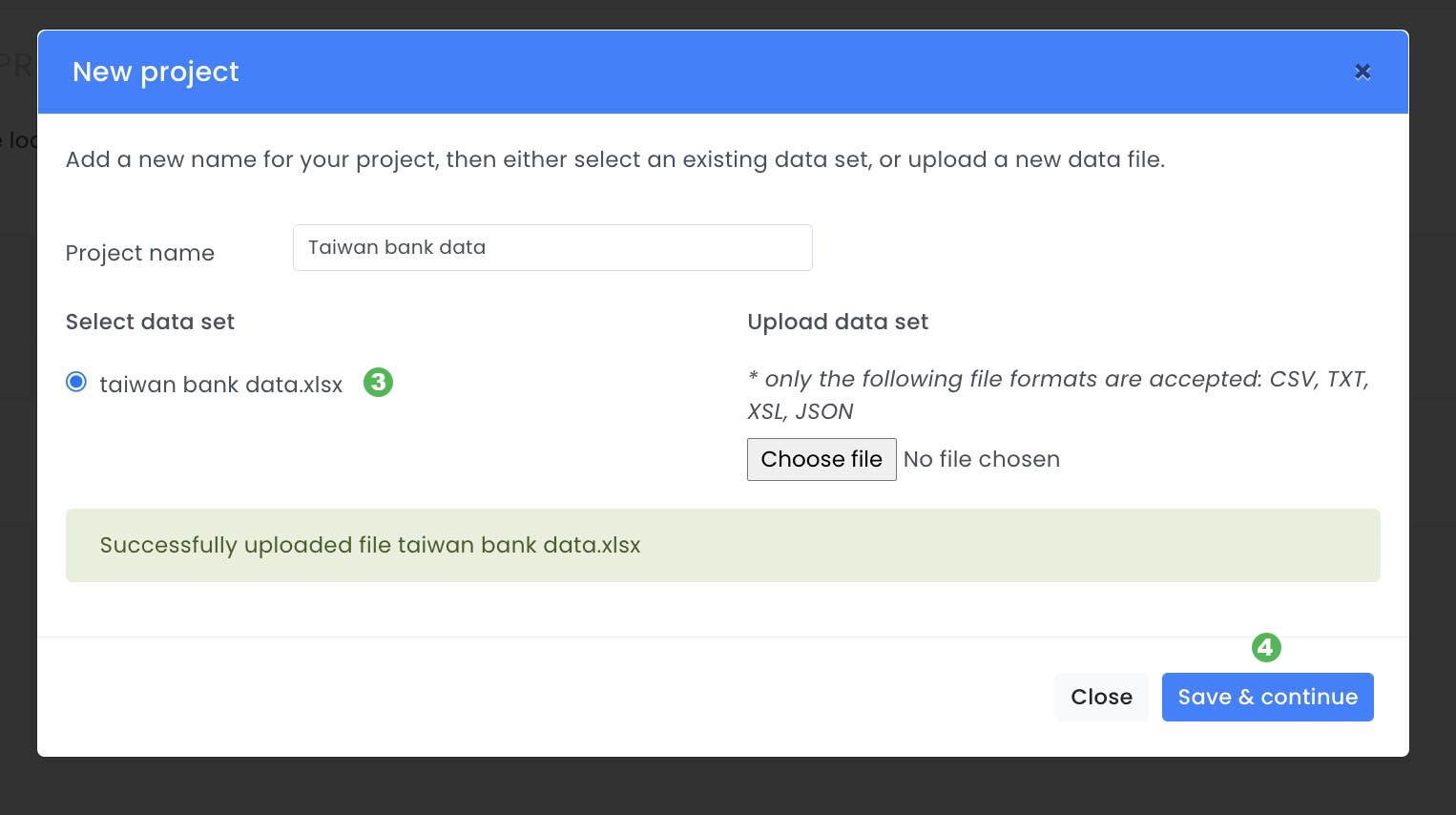
A pop-up will appear where a project name ( 1 ) must be given then a data set needs to be uploaded ( 2 ) or selected ( 3 ). In this case we will use the public dataset UCI ML data set from the Taiwanese Bank that has been described earlier. After the dataset has been selected you can click Save & continue ( 4 ).
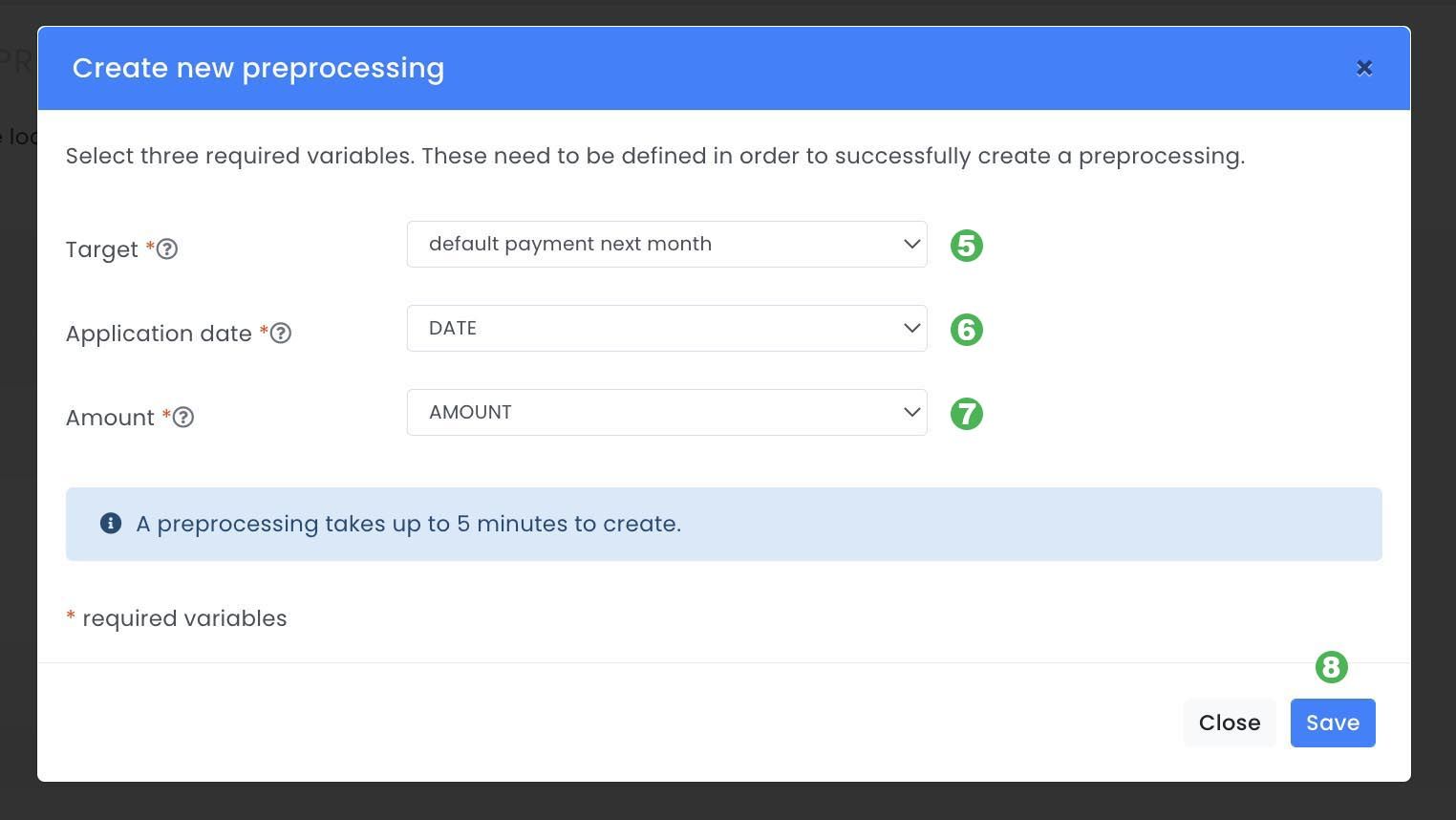
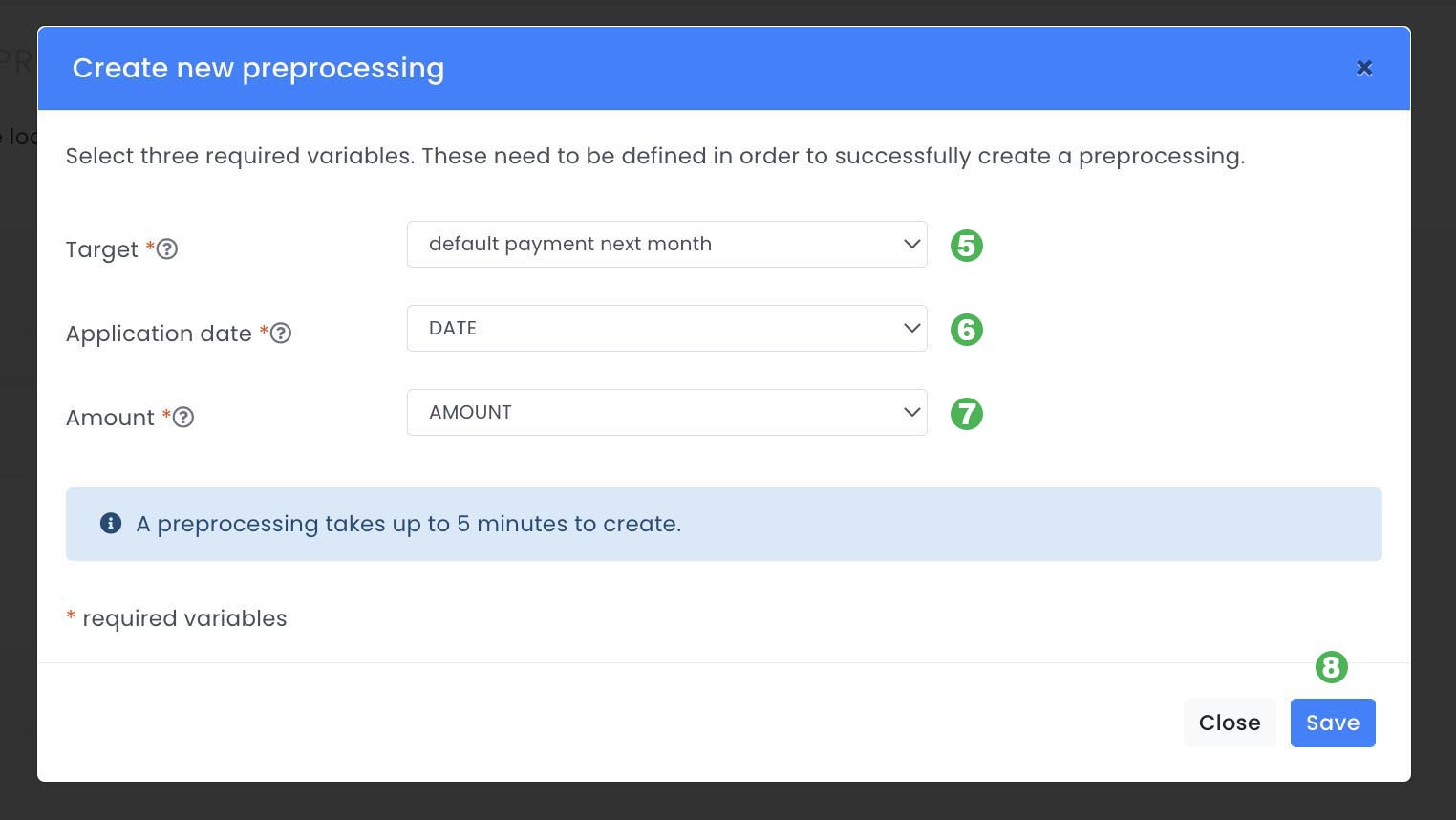
A new pop-up will appear where three required variables from your dataset must be chosen, target, application date and amount.
1: Target: A column in the data set representing the variable we will try to predict. In this case we will use the variable default.payment.next.month, since this is what we want to predict. ( 5 )
2: Application date: A column in the data set representing application date is required to split the data between training and test. In this case we will use the variable date. (.6 )
3: Amount: A column in the data set representing loan amount must exist in order to be able to use the risk converter. In this case we will use the variable amount. ( 7 )
After the three variables are selected, click Save ( 8 ) and the Evispot ML platform will do an exploratory data analysis which could take a few minutes.
Tips
Application date and amount will not be used in the model training, they will only be used to help build a robust and accurate model in the form of Out-Of-time test and risk converter. (this will be covered later on)
Now that the dataset has been imported, let’s discover how Evispot ML allows you to further understand the uploaded dataset. Doing so will allow us to further explore the second step of the Evispot ML workflow: visualize data.
We exist to ensure that decisions are given in an accurate, transparent, ethical & fair manner.

{kind=link}
{kind=link}
{kind=link}
{kind=link}