Disparate impact analysis
Disparate impact analysis (DIA) also referred to Adverse Impact analysis is a technique to evaluate fairness. It is used to notify when members of a protected group or minority (e.g gender, praticulare race etc) receive unfavorable decisions, in lending, an example would be whether a person is denied or accepted a loan. To conduct a DIA many different statistical values are calculated from confusion matrices. These metrics will help us understand the model overall performance and how it behaves when predicting:
-
Default correctly
-
Non-default correctly
-
Default incorrectly*
-
Non-default incorrectly**
* A model that denies a financial healthy borrower, which for the bank will result in lost interest and fees
** A model that accept a financial not healthy borrower, which for the bank often results in credit losses
To be able to calculate confusion matrices we need to translate the model prediction to a decision. To make a decision using a model-generated predicted probability, a numeric cutoff must be specified, which decides if an applicant will default or not. Cutoffs play a crucial role in DIA, since they impact the underlying statistics to calculate disparity. There are many accepted ways to set the cutoff score, but when working with imbalanced data, which is very common in the finance industry, it is sometimes seen as a more robust way to use the maximized F1 score, since it gives a good balance between true positive rate and precision.
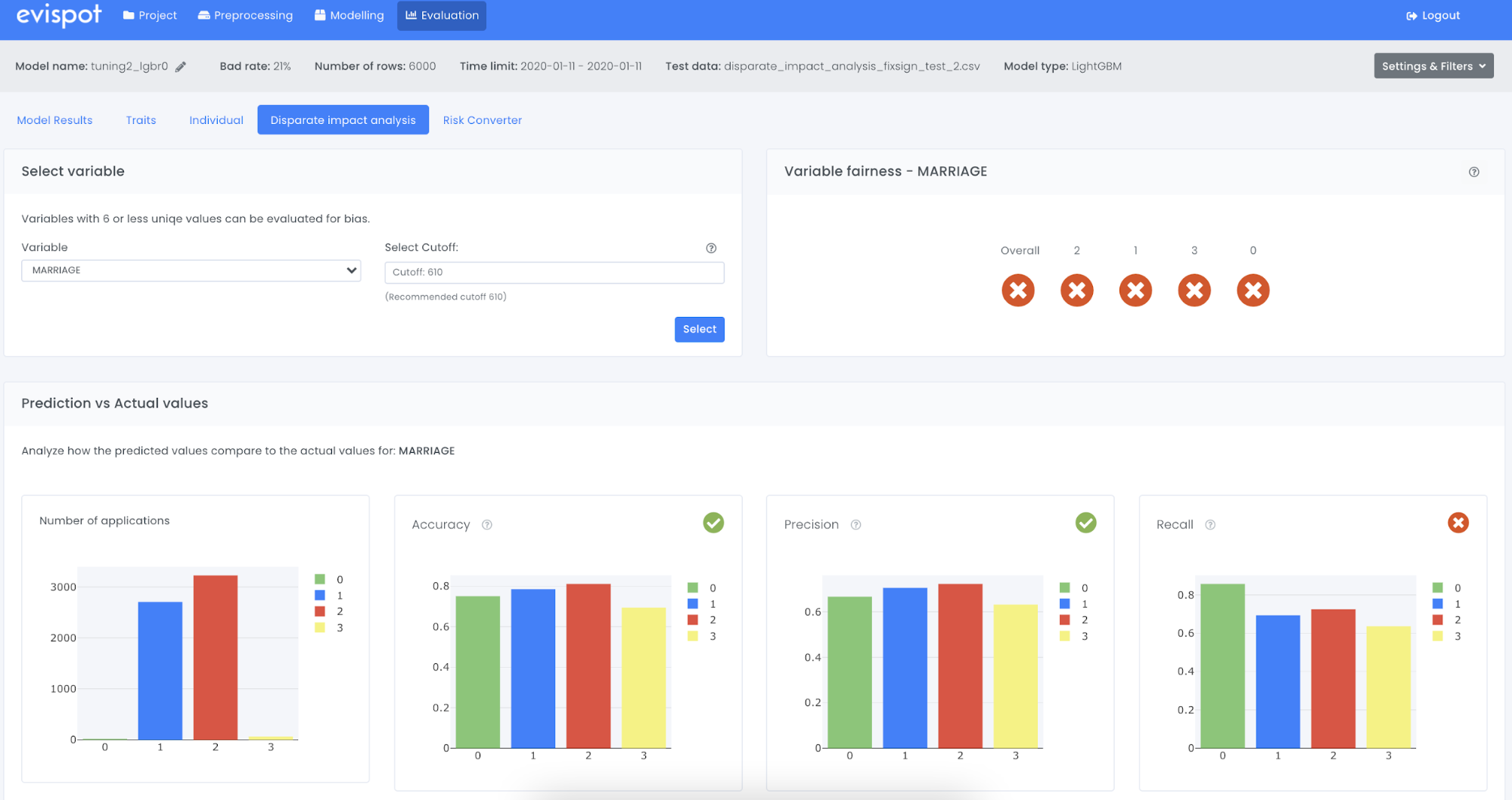
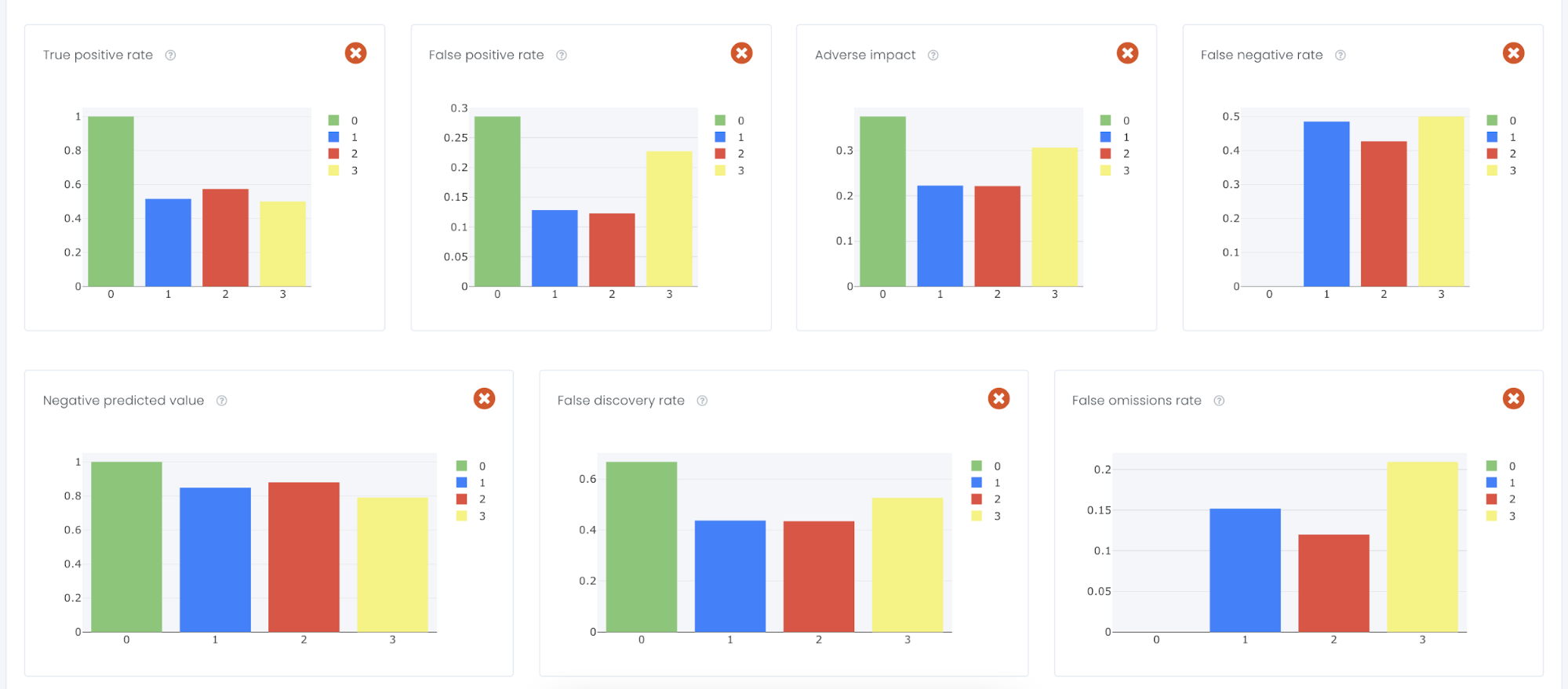
To calculate disparity we compare the confusion matrix for each class for a user-defined reference level and to user-defined thresholds. In this example we have used F1 score as a user-defined threshold and the user-defined reference we have chosen the four-fifths rule. That means that thresholds are set such that metrics 20% lower or higher than the reference level metric will be flagged as disparate. Below you will see a table of all the statistics that is calculated from a confusion matrix.


Disparate impact analysis in Evispot ML-platform
A public dataset UCI ML Data set from Taiwanese Bank has been used to illustrate how to conduct a disparate impact analysis using the Evispot ML platform. The dataset contains demographic data such as age, education gender, history of past payment and a target variable: default_payment_next_month.
If the model is built using variable gender or marital status, it may not be considered compliant in regulatory environments since these variables can introduce intentional bias to the model. Hence, gender and marital status will not be used in the model built in the evispot ML platform but it is still possible to conduct a DIA as long as gender is included in the file that is uploaded to the evispot ML platform.
After the dataset has been uploaded to the evispot ML-platform, ignored variable gender and marital status, and used the automated feature engineering/selection and model training I am navigating to the Disparate impact analysis tab to see if our model is fair or not.
As a starting point I chose to look into gender or sex. As can be seen in the picture below, the software has already calculated confusion matrices and all necessary KPIs to conduct the analysis. The default calculations are based on the maximized F1 score cutoff and four-fifth rule, but it could be changed to your own preferences. The result can be found under the Variable fairness section and more detailed statistics can be analysed in the plots under section Prediction vs Actual values. As can be seen the trained model has no unintentional bias according to the DIA.


Another variable to look into is Marriage, e.g single, divorced, married. As can be seen the model has failed in numerous KPIs and in reality, if this model goes to production it will favor a certain Marital Status over the other (even though it was not one of the inputs) and we have created a model with unintentional bias.


We exist to ensure that decisions are given in an accurate, transparent, ethical & fair manner.

{kind=link}
{kind=link}
{kind=link}
{kind=link}