Modelling
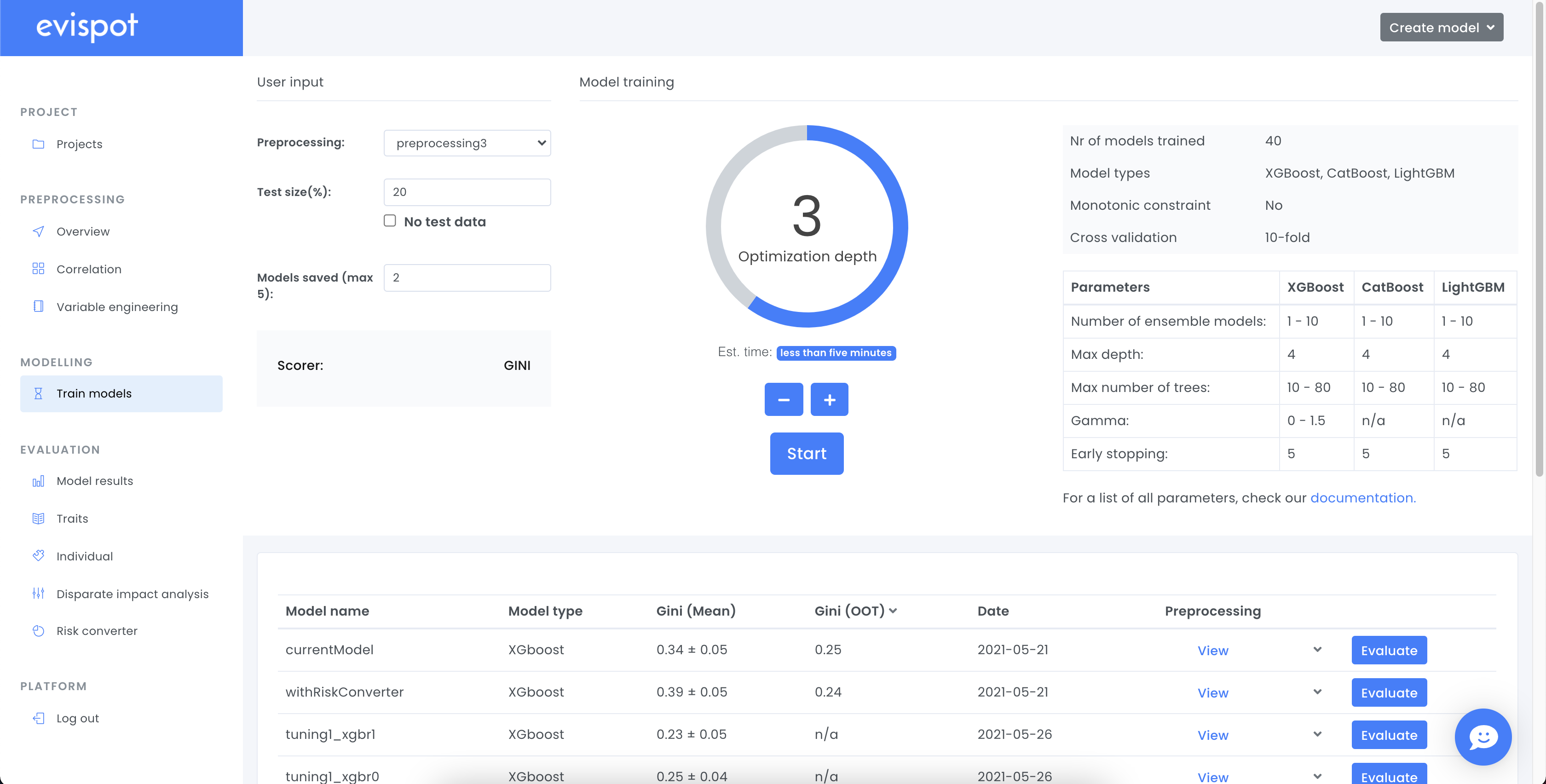
In the modelling view AI models can be created. Either by running the automatic model optimization, which lets the evispot AI platform automatically train and optimize different AI models or use expert settings to customize an AI model. The best results from the model run will be shown in the leaderboard table.
Happening under the hood
Automatic Model Optimization
When the start button from the modelling view is clicked, the Evispot AI platform will first separate the data set into training, validation and test set, do data sampling, and finally test different AI models using different hyperparameters using a variance of grid search. The Evispot AI platform will show detailed information about the top models. Each model can then be validated more thoroughly in the evaluation view.
Split data set into training and test set.
When clicking at the start button, the Evispot AI platform will split the data into a training and test set. Test set will either be created using
- The variable “application date” variable. By default 20% of the most recent data points will be used as a test set (e.g out-of-time test set).
- If the variable “application date” only contains the same date, the dataset will be shuffled and then split into a test set (default 20%) and training set.
- Use all data to create a model, this requires that a separate test set is uploaded after model training to evaluate model performance.
The training set is the data which contains all the data points available to create a model during training. After splitting the data set into training and testing the next step is the data sampling.
Data sampling
Evispot AI platform does not perform any type of data sampling unless the data is highly imbalanced (for improved accuracy).
However, within many financial decisions such as credit decisions, portfolio analyses, predicting churn, it is most likely that an unbalanced data set is used. An unbalanced data set means that there exist few data points including a specific target variable, for instance in credit decision it will most likely be more non-defaults compared to defaults. This will become a challenge when AI algorithms try to identify rare cases in big data sets. Due to the disparity of classes the algorithms tend to categorize all examples into the class with more examples, while at the same time giving the false sense of a highly accurate model.
Evispot AI platform solves this problem by only allowing the model to see a subset of non-defaults, meaning that a data set containing the same number of examples is created. This technique is called undersampling. However, the disadvantage of undersampling is that we remove data points from the data set. To avoid this, we use bagging, which means that we create several data sets using undersampling. As a result, we will eventually have several data sets, where applications with defaults will overlap between the data sets, while non-defaults will often be unique in each data set. The tree model Random Forest, is one of the most well-known models that uses bagging, and is very effective in high variance data sets. By default, the number of bags is automatically determined, but can be specified in modelling expert settings.
After data sampling different AI models will be tested and trained (see supported models be)
Supported models
XGBoost
XGBoost is a supervised learning algorithm that implements a process called boosting to yield accurate models. Boosting refers to the ensemble learning technique of building many models sequentially, with each new model attempting to correct for the deficiencies in the previous model. In tree boosting, each new model that is added to the ensemble is a decision tree. XGBoost provides parallel tree boosting (also known as GBDT, GBM) that solves many data science problems in a fast and accurate way. For many problems, XGBoost is one of the best gradient boosting machine (GBM) frameworks today.
Follow this link to XGBoost library
LightGBM
LightGBM is a gradient boosting framework developed by Microsoft that uses tree based learning algorithms. It was specifically designed for lower memory usage and faster training speed and higher efficiency. Similar to XGBoost, it is one of the best gradient boosting implementations available.
Follow this link to LightGBM library
CatBoost
CatBoost is an algorithm that uses gradient boosting on decision trees developed by Yandex researchers and engineers. Key features, categorical variables support, fast and scalable GPU version,
For all models we will use cross validation to make sure the models are not overfitted (see more information in internal validation technique)
Follow this link to Catboost library
Validation technique
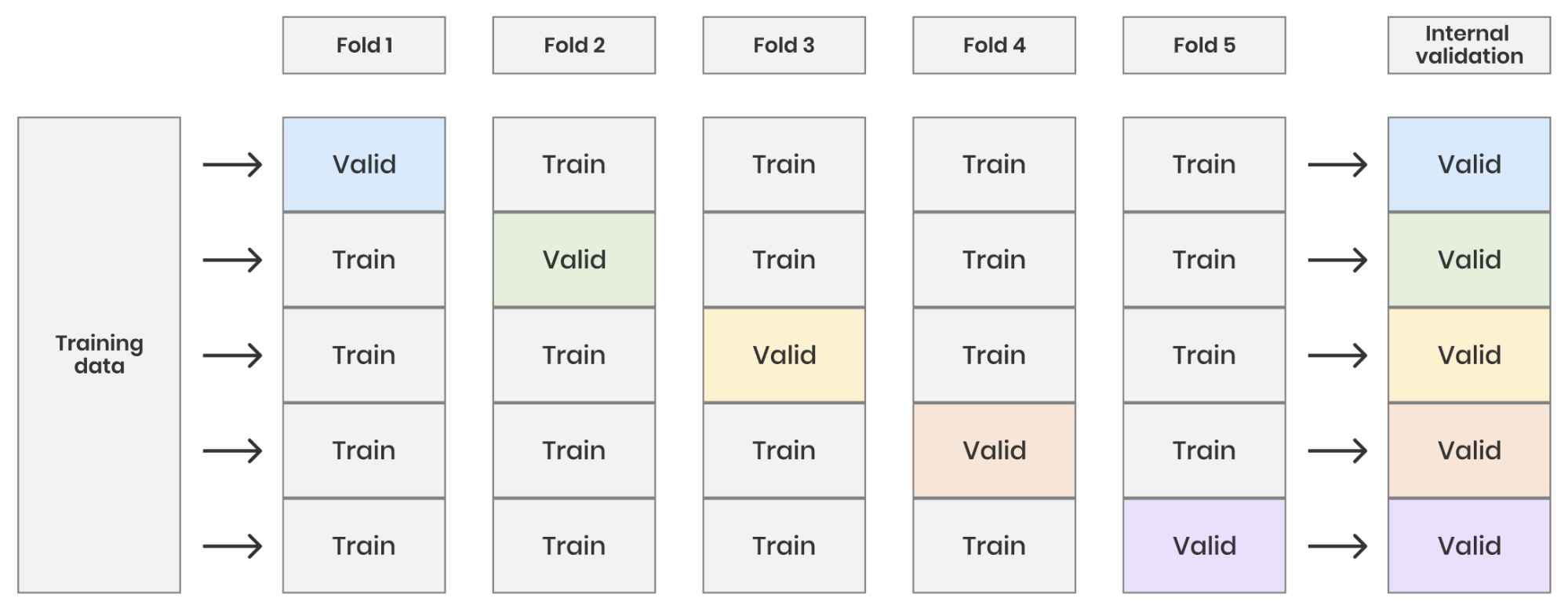
The platform uses monte carlo cross validation to make sure the models are robust in production. Monte-carlo cross validation works in the following way:
- Split training data according to the percentage that was given when starting a model training, (default is 20%).
- Fit the model on the training data set and calculate gini, AUC, Kolmogorov-smirnov, Log loss mean squared error, mean absolute error and ROC curves using the fitted model on the test data.
- Repeated 10 times.
The following visualisation shows an example of cross validation with 5 iterations. However using monte-carlo the same data can be selected more than once in the test set or even never at all. The advantage being that you can do any number, and any training size, of cross validation splits and still have unique data sets.
Automatic Model Tuning
When the platform starts to train a model, it will test all supported models using hyperparameter optimization technique grid search. Grid search means that each model runs through a number of different hyperparameters and based on a scoring metric returns the best model. The default the scoring metric is gini.
We exist to ensure that decisions are given in an accurate, transparent, ethical & fair manner.

{kind=link}