Glossary
Acceptance Rate
Acceptance Rate is the number of accepted loans divided by the total number of loans.
Accuracy
Accuracy is a performance metric that allows you to evaluate how good your model is. It’s used in classification models and is the ratio of:
Tip: Accuracy is highly sensitive to class imbalances in your data.
Area under the ROC Curve (AUC)
The AUC is the area under the ROC curve and is a performance measure that tells you how well your model can classify different classes. The higher the AUC the better the model.

Average broker probability
A broker or a loan broker is a third party that sometimes acts as a go-between for a borrower and a lender. Some lenders, including both traditional and non-traditional lenders, use brokers to provide the necessary applications, documents, and processes to help borrowers through the loan process.
In this case we include the average probability that a loan taker is coming from a loan broker.
Average Prepayment Probability
Prepayment or the churn rate, also known as the rate of attrition or customer churn, is the rate at which customers stop doing business with an entity. It is most commonly expressed as the percentage of service subscribers who discontinue their subscriptions within a given time period. For lenders churn rate is equal to people who move their current loan to another financial institution and pre-pays their outstanding debt, which might return a non-profitable situation for the first lender.
Hence should the probability of pre-payment be included in a bank’s profitability and pricing calculations. Each loan has a dynamic and individual risk of pre-payment but as of today the average pre-payment risk is used in the calculations.
Broker Commision
Broker commision , also known as broker fees, are based on a percentage of the transaction, as a flat fee, or a hybrid of the two. Brokerage fees vary according to the industry and type of broker.
For unsecured loans the fees are usually between 3% and 5% of the loan amount.
Capital Cover Rate
Capital Cover Rate or Capital Adequacy Ratio (CAR) is a measurement of a bank’s available capital expressed as a percentage of a bank’s risk-weighted credit exposures. The capital adequacy ratio, also known as capital-to-risk weighted assets ratio (CRAR), is used to protect depositors and promote the stability and efficiency of financial systems around the world.
CAR is critical to ensure that banks have enough cushion to absorb a reasonable amount of losses before they become insolvent. CAR is used by regulators to determine capital adequacy for banks and to run stress tests. Two types of capital are measured with CAR. Tier-1 capital can absorb a reasonable amount of loss without forcing the bank to stop its trading, while tier-2 capital can sustain a loss if there’s a liquidation. The downside of using CAR is that it doesn’t account for the risk of a potential run on the bank, or what would happen in a financial crisis.
Categorical variables
A categorical variable is an input variable that has a discrete set of possible values. For example, if your variable is ‘season’ the possible values it can take are ‘Winter’, ‘Spring’, ‘Summer’ and ‘Autumn’.
Confusion Matrix
A confusion matrix helps to illustrate what kinds of errors a classification model is making.
If you have a binary classifier model that distinguishes between a positive and a negative class, you can define the following 4 values depending on the actual vs predicted class.

Confusion matrix
The resulting matrix has 4 fields known as:
- True Positives (TP)
- True Negatives (TN)
- False Positives (FP),
- False Negatives (FN)
Different combinations of these fields result in a number of key metrics, including: accuracy, precision, recall, specificity and f1 score.
The confusion matrix is a compact but very informative representation of how your classification model is performing. It is the go to tool for evaluating classification models.
Cost of prepayment
The missed-out income at the event of a pre-payment is expressed as a cost. The cost of pre-payment is the average missed-out income.
Cross validation
To assess how a model will perform in practice we need to validate it against an independent data set. This is commonly done by splitting the data into training and test set. A model is then trained on the training set and validated on the test set. However this method still leaves the question: what if the model was only good on this particular test set? To circumvent this issue we repeat the method multiple times, with differently sampled test sets, and thus we can measure the expected mean and variance between the model performances. This algorithm is known as Cross Validation, and allows us to better understand how a model trained on all the data will perform.

Distribution plot
The distribution plot is suitable for comparing range and distribution for groups of numerical data. Data is plotted as value points along an axis.
Expected Loss
The Expected Loss is calculated as: EAD x PD x LGD = Expected Loss
Exposure at Default (EAD)
Exposure at default (EAD) is the total value a bank is exposed to when a loan defaults. Using the internal ratings-based (IRB) approach, financial institutions calculate their risk. Banks often use internal risk management default models to estimate respective EAD systems. Outside of the banking industry, EAD is known as credit exposure.
EAD is the predicted amount of loss a bank may be exposed to when a debtor defaults on a loan. Banks often calculate an EAD value for each loan and then use these figures to determine their overall default risk. EAD is a dynamic number that changes as a borrower repays a lender.
F1-score
In theory a good model (one that makes the right predictions) will be one that has both high precision, as well as high recall. In practice however, a model has to make compromises between both metrics. Thus, it can be hard to compare the performance between a model with high recall and low precision versus a model with low recall and high precision.
F1-score is a metric that summarizes both precision and recall in a single value, by calculating their harmonic mean, which allows it to be used to compare the performance across different models. It’s defined as:

False Negatives (FN)
Assume a data set that includes examples of a class Non-default and examples of class Default. Assume further that you’re evaluating your model’s performance to predict examples of class Non-default.
False negatives is a field in the confusion matrix which shows the cases when the actual class of the example was Default and the predicted class for the same example was Non-default.
False Positive (FP)
Assume a data set that includes examples of a class Non-default and examples of class Default. Assume further that you’re evaluating your model’s performance to predict examples of class Non-default.
False positives is a field in the confusion matrix which shows the cases when the actual class of the example was Default and the predicted class for the same example was Non-default.
Feature
A feature is an input variable. It can be numeric or categorical. For example, a house can have the following features: number of rooms (numeric), neighbourhood (categorical), street name (categorical). The term “variable” throughout the Evispot platform.
“Feature” and “variable” are different terms for the same thing. “Feature” is more common in machine learning, whereas “variable” is more common in statistics.
Financing cost
Financing cost or the cost of funds is a reference to the interest rate paid by financial institutions for the funds that they use in their business. The cost of funds is one of the most important input costs for a financial institution since a lower cost will end up generating better returns when the funds are used for short-term and long-term loans to borrowers.
The spread between the cost of funds and the interest rate charged to borrowers represents one of the main sources of profit for many financial institutions.
Gini
The Gini coefficient is a well-established method to quantify the inequality among values of a frequency distribution, and can be used to measure the quality of a binary classifier. Gini is measured between 0 and 1. A Gini index of 0 expresses perfect equality (or a totally useless classifier), while a Gini index of 1 expresses maximal inequality (or a perfect classifier). A gini of 1 should however be met with suspicion. The closer to 1 we get, the better the results are.
The Gini index is based on the Lorenz curve. The Lorenz curve plots the true positive rate (y-axis) as a function of percentiles of the population (x-axis).
The Gini is calculated by the following equation:
Gini = (AUC x 2) -1
The Lorenz curve represents a collective of models represented by the classifier. The location on the curve is given by the probability threshold of a particular model. (i.e., Lower probability thresholds for classification typically lead to more true positives, but also to more false positives.)

The Gini index itself is independent of the model and only depends on the Lorenz curve determined by the distribution of the scores (or probabilities) obtained from the classifier.
Tip The higher gini, the better classifier, however if you get a gini of 1, you should be very suspicious and most likely a variable exist in the data set that is equivalent with your target variable, (e.g tarket leakage)
Hyperparameter
Hyperaparameter is a parameter whose value is used to control the learning process of a specific AI model. A hyperparameter has to be set / fixed before starting the training process.
Information Value
Information Value is a measurement of the predictive power of a variable is and is calculated using the below formula:
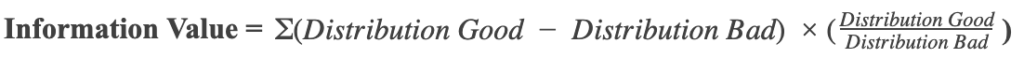
Kolmogorov-Smirnov Statistics (KS)
The Kolmogorov–Smirnov test (KS) is a statistical test to check that two data samples come from the same distribution. The advantage of this test is that it’s non-parametric in nature, therefore it is distribution agnostic. Thus, we are not concerned if the underlying data follows any specific distribution.
Read more about Kolmogorov-Smirnov here
Log loss
Log loss, also called logistic regression loss or cross-entropy loss, is defined on probability estimates.The metric looks at how well a model can classify a binary target, log loss evaluates how close a model’s predicted values (uncalibrated probability estimates) are to the actual target value. For example, does a model tend to assign a high predicted value like .80 for the positive class, or does it show a poor ability to recognize the positive class and assign a lower predicted value like .50? Log loss can be any value greater than or equal to 0, with 0 meaning that the model correctly assigns a probability of 0% or 100%.
Read more about log loss here
Loss Given Default (LGD)
Loss given default (LGD) is the amount of money a bank or other financial institution loses when a borrower defaults on a loan, depicted as a percentage of total exposure at the time of default. A financial institution’s total LGD is calculated after a review of all outstanding loans using cumulative losses and exposure.
The loss given default (LGD) is an important calculation for financial institutions projecting out their expected losses due to borrowers defaulting on loans.
Marketing cost
Marketing costs are the all expenses that the company makes to market and sell its products and develop and promote its brand. These marketing costs or expenses include expenses incurred to change the title of goods, promotion of goods, advertisements,, distribution of products etc.
Max
The max value refers to the maximum value and is calculated for each numerical variable in a data set.
Mean Absolute Error (MAE)
The mean absolute error (MAE) is an average of the absolute errors. The MAE units are the same as the predicted target, which is useful for understanding whether the size of the error is of concern or not. The smaller the MAE the better the model’s performance.
Tip: MAE is robust to outliers. If you want a metric that is sensitive to outliers, try mean squared error (MSE).
Mean Squared Error (MSE)
The MSE metric measures the average of the squares of the errors, that is the average squared difference between the estimated values and the actual value. The MSE is a measure of the quality of an estimator—it is always non-negative, and values closer to zero are better.
Tip: MSE is sensitive to outliers. If you want a more robust metric, try mean absolute error (MAE).
Median
The median is calculated for each numerical variable in a data set. See definition here
Min
The min value refers to the minimum value and is calculated for each numerical variable in a data set.
Other overhead costs
Other overhead costs or operating costs are associated with the maintenance and administration of a business on a day-to-day basis. Operating cost is a total figure that include direct costs of goods sold (COGS) from operating expenses (which exclude direct costs), and so includes everything from rent, payroll, and other overhead costs to raw materials and maintenance expenses. Operating costs exclude non-operating expenses related to financing such as interest, investments, or foreign currency translation.
Out-of-time Test
Out-of-time test is the method of training a model on data from the earlier part of the time-interval and testing it against the later, so called out-of-time test set. The purpose is to create a testing scenario where the model and test set simulates how the model would perform in real time.
Overfitting
Overfitting is the phenomenon of a model not performing well, i.e., not making good predictions, because it captured the noise as well as the signal in the training set. In other words, the model is generalizing too little and instead of just characterizing and encoding the signal it’s encoding too much of the noise found in the training set as well. (Another way to think about this is that the model is trying to fit ‘too much’ to the training data).
This means that the model performs well when it’s shown a training example (resulting in a low training loss), but badly when it’s shown a new example it hasn’t seen before.
Partial dependence
Partial dependence is a measure of the average model prediction with respect to an input variable. Partial dependence plots display how machine-learned response functions change based on the values of an input variable of interest while taking nonlinearity into consideration and averaging out the effects of all other input variables. It shows whether the relationship between the target and a variable is linear, monotonic or more complex.
Probability of Default (PD)
Probability of Default is the likelihood over a specified period, usually one year, that a borrower will not be able to make scheduled repayments. It can be applied to a variety of different risk management or credit analysis scenarios. Sometimes also referred to as Default probability, it is dependent, not only on the borrower’s characteristics but also on the economic environment.
Profit per loan
Profit per loan is the total profit calculated for every loan expressed as a percentages. The profit per loan is calculated by subtracting all the revenues with all the cost.
Profit per loan = (Loan Income – Loan cost)/Loan amount
Loan cost besides the user added costs includes the Expected loss based on the PD of each loan.
Return on Equity (ROE)
Return on equity (ROE) is a measure of financial performance calculated by dividing net income by shareholders’ equity. Because shareholders’ equity is equal to a company’s assets minus its debt, ROE is considered the return on net assets. ROE is considered a measure of the profitability of a corporation in relation to stockholders’ equity.
ROE is expressed as a percentage and can be calculated for any company if net income and equity are both positive numbers. Net income is calculated before dividends paid to common shareholders and after dividends to preferred shareholders and interest to lenders.
Return on Equity = Net Income / Shareholders’ Equity
Where Shareholders Equity or Capital Allocation is Loan Amount * Capital Cover rate.
Return On Risk Adjusted Capital (RORAC)
The return on risk-adjusted capital (RORAC) is a rate of return measure commonly used in financial analysis, where various projects, endeavors, and investments are evaluated based on capital at risk. Projects with different risk profiles are easier to compare with each other once their individual RORAC values have been calculated. The RORAC is similar to return on equity (ROE), except the denominator is adjusted to account for the risk of a project.
Return on Risk Adjusted Capital= Net Income / Risk-Weighted Assets
Where Risk-Weighted Assets is Loan Amount * Probability of Default, also known as value at risk.
Risk-Weighted Asset
Risk-weighted assets are used to determine the minimum amount of capital that must be held by banks and other financial institutions in order to reduce the risk of insolvency. The capital requirement is based on a risk assessment for each type of bank asset.
ROC curve
A receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier system as its discrimination threshold is varied. It is created by plotting the fraction of true positives out of the positives (TPR = true positive rate) vs. the fraction of false positives out of the negatives (FPR = false positive rate), at various threshold settings.
Tip A larger area under the curve essentially means a better model, however the symmetry (in relation to the diagonal) and stability of the curve is also relevant.

Shapley value
Shapley explanations are a technique with credible theoretical support that presents consistent global and local variable contributions. Local numeric Shapley values are calculated by tracing single rows of data through a trained tree ensemble and aggregating the contribution of each input variable as the row of data moves through the trained ensemble. For classification problems, Shapley values sum to the prediction of the Evispot AI model before applying the link function. Global Shapley values are the average of the absolute Shapley values over every row of a data set.
Read more about Shapley here
Standard Deviation
The Standard deviation is calculated for each numerical variable in a data set. See definition here
Swap-in
Swap-in is a previously denied loan which with the newly developed model and/or settings will be accepted. Since the swap-in previously was declined there is no actual label available.
Swap-out
Swap-out is a previously accepted loan which with the newly develop model and/or setting will be denied. SInce the swap-out previously was accepted is an actual label available.
Target Leakage
Target leakage, sometimes called data leakage, is one of the most difficult problems when developing an AI model. It happens when you train your algorithm on a data set that includes information that would not be available at the time of prediction when you apply that model to data you collect in the future. Since it already knows the actual outcomes, the model’s results will be unrealistically accurate for the training data, like bringing an answer sheet into an exam.
Test data set
The test data set is used for the final stage scoring and is the data set for which model metrics will be computed against. Test set predictions will be available at the end of the experiment. This data set is not used during training of the modeling pipeline.
Training data set
A training set is a subset of your data set which contains all the data points available to create a model during training.
True Negatives (TN)
Assume a data set that includes examples of a class Non-default and examples of class Default. Assume further that you’re evaluating your model’s performance to predict examples of class Non-default.
True negatives is a field in the confusion matrix which shows the cases when the actual class of the example was Default and the predicted class for the same example was also Default.
True Positive (TP)
Assume a data set that includes examples of a class Non-default and examples of class Default. Assume further that you’re evaluating your model’s performance to predict examples of class Non-default.
True positives is a field in the confusion matrix which shows the cases when the actual class of the example was Non-default and the predicted class for the same example was also Non-default.
Underfitting
Underfitting is the phenomenon of a model not performing well, i.e., not making good predictions, because it wasn’t able to correctly or completely capture the signal in the training set. In other words, the model is generalizing too much, to the point that it’s actually missing the signal.
This means that the model doesn’t perform well on training examples (resulting in a high training loss), nor on examples it hasn’t seen before (resulting in a high validation loss).
Undersampling
It’s the process of balancing a data set by discarding examples of the overrepresented class so that each has the same amount of examples.
A balanced data set allows a model to learn equal amounts of characteristics from each one of the classes represented in the data set, as opposed to one class dominating what the model learns.
Variable engineering
Variable engineering is the secret weapon that advanced data scientists use to extract the most accurate results from algorithms. Evispot AI platform employs a library of algorithms and variable transformations to automatically engineer new, high value variables for a given data set.
See Variable Transformation for more information
Variable selection
Adding variables to your data set can improve the accuracy of your AI model, especially when the model is too simple to fit the existing data properly. However, it is important to focus on variables that are relevant to the problem you’re trying to solve and to avoid focusing on those that contribute nothing. Good variable selection eliminates irrelevant or redundant columns from your data set without sacrificing accuracy.
The benefits of variable selection for AI include:
- Reducing the chance of overfitting
- Improving algorithm run speed by reducing the CPU, I/O, and RAM load the production system requires to build and use the model by lowering the number of operations needed to read and preprocess data and perform data science.
- Increasing the model´s interpretability by revealing the most informative factors driving the model´s outcome
In the evispot AI platform recursive variable elimination is used to determine which variables are most important. The AI algorithm and hyperparameter settings that are used depends on the uploaded data.
Volume Rate
Volume Rate is the accepted loan volume divided by the total loan volume.
We exist to ensure that decisions are given in an accurate, transparent, ethical & fair manner.
