Variable engineering
The Evispot AI automatic feature engineering means that the software creates hypotheses from the uploaded data set using different transformation techniques unique for categorical and numerical variables. (See variable transformation list for detailed information)
After the automatic feature engineering the software might have created thousands of variables from the original data set. To find out which variables to use in the model, an automatic feature selection starts, validating all created hypotheses and recommends the best data set to use when building models. In the Evispot AI platform a variant of Recursive Variable Elimination is used to determine which variables to use when a model is built. The Recursive Variable Elimination uses different models and hyperparameters depending on the uploaded data set. To avoid overfitting, 5 fold monte carlo cross validation is used for each iteration. (see internal validation technique for more information)
If the uploaded data set is larger than 50 000 rows, the automatic hypothesis testing will be performed on a subset of the data set. The software will split the data in training and validation sets according to the monte-carlo subsampling technique. The same monte carlo split is used in each step of the algorithm in order for the feature selection to be consistent between iterations.
Variable transformation
The following variable transformation/hypothesis are generated in the Evispot AI platform
Interactions Transformer
The Interactions Transformer divides two numerical columns in the data to create a new variable. This transformation uses a smart search to identify which variable pairs to transform. Only interactions that improve the model score are kept.
Original Transformer
The Original Transformer applies an identity transformation to a numeric column.
Date Original Transformer
The Date Original Transformer retrieves date values and will create the following variables: month, day of the month, day of the week and if it is a weekday or not.
One Hot Encoding Transformer
The One-hot Encoding transformer converts a categorical column to a series of boolean variables by performing one-hot encoding. The boolean variables are used as new variables.
Weight Of Evidence Transformer
The Weight of Evidence Transformer calculates Weight of Evidence for each value in the categorical column(s). The Weight of Evidence is used as a new variable. Weight of Evidence measures the “strength” of a grouping by separating good and bad and is calculated by taking the log of the ratio of the good and bad distributions of a grouping.
Missing values are imputed
During Training
Evispot AI will treat missing values differently depending which type a variable has. For numerical variables the median will be used, for categorical variables a separate missing value category will be used and for weight of evidence variable the mean of the encoding will be used.
In production
If missing data is present during training, these tree-based algorithms learn the optimal direction for missing data for each split (left or right). This optimal direction is then used for missing values during scoring. If no missing data is present during scoring (for a particular variable), then the variable will use the median value if the value is missing.
Predicting on a Categorical Level Not Seen During Training
Categories of a categorical variable not seen in training will be treated as missing values and put in the missing values bin.
WoeEncoded variables will have their missing values/categories not seen in training represented by the mean of the WoeEncoding, thus limiting their impact on the scoring.
Variable engineering
The variable engineering view provides tools to analyse the automatic variable engineering process.
Variable engineering plot
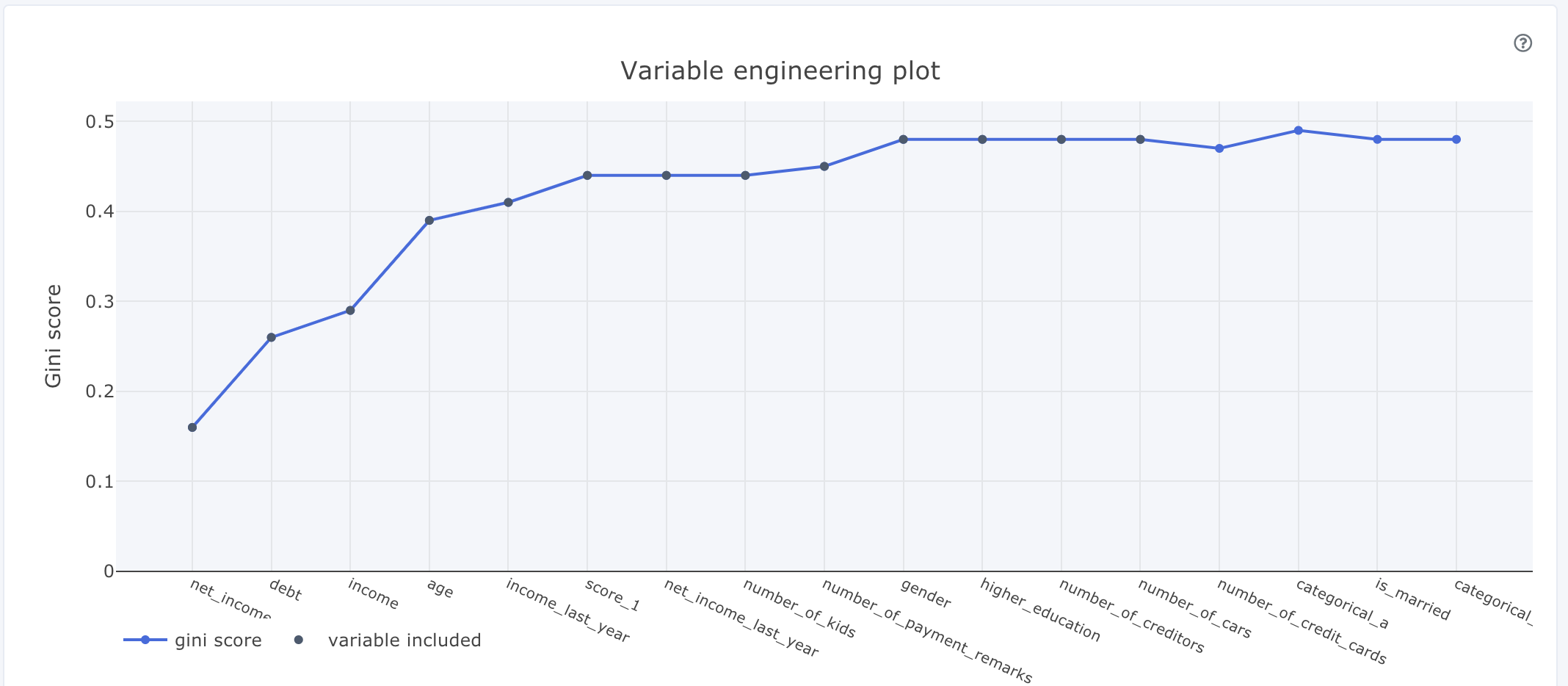
X-axis: all variables that have been used in the variable engineering process, where the most important variable is to the left and least importance to the right.
Y-axis: gini score / model score.
We exist to ensure that decisions are given in an accurate, transparent, ethical & fair manner.
